An AI agent found 21 ways to attack FFmpeg, the codec library inside almost everything
DepthFirst's agent surfaced 21 FFmpeg zero-days for about $1,000. One 183-byte packet hits RCE. The deeper story is who pays the volunteers who fix them.
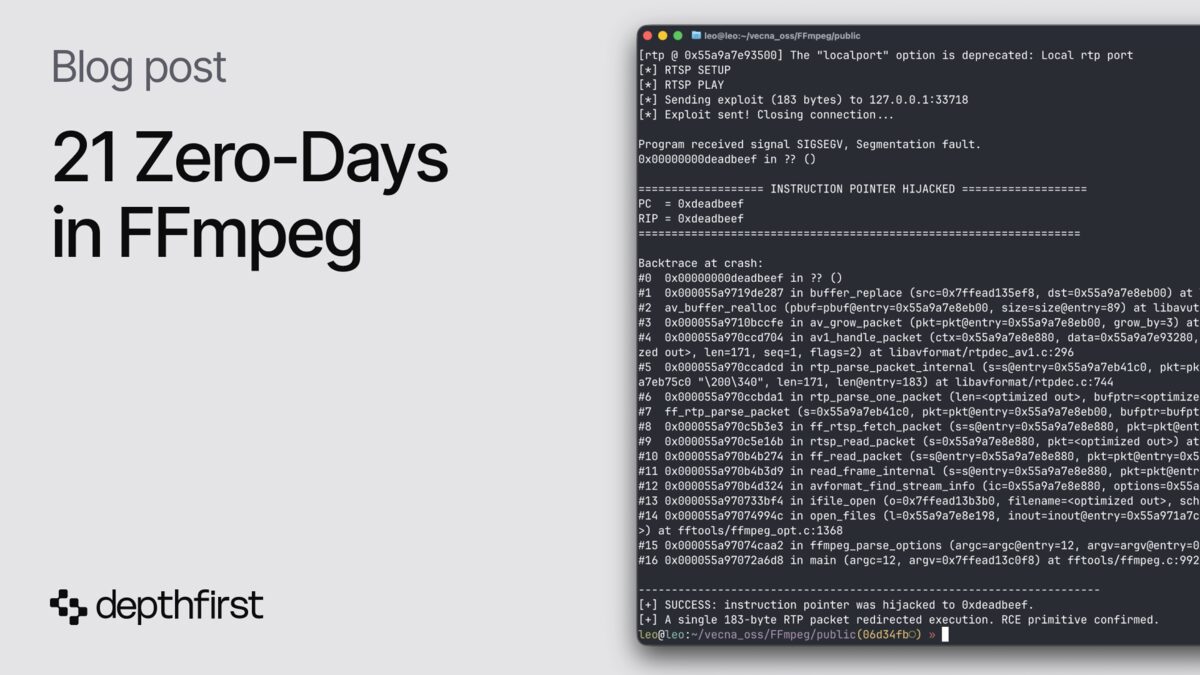
A security firm called DepthFirst just disclosed 21 zero-day vulnerabilities in FFmpeg, the media library quietly running inside your browser, your phone, VLC, and most of the servers that touch a video file. It found them with an AI agent, and it says the whole run cost about $1,000.
That number is the hook, but it’s not the story. The story is that FFmpeg parses untrusted media for basically the entire internet, its attack surface is enormous, and the people who patch it are a small group of volunteers. When a researcher (or an automated agent, or an attacker) finds a flaw, the fix lands on those volunteers’ plates. The companies shipping FFmpeg to billions of users mostly don’t help write it.
What FFmpeg actually is
If you’ve never typed ffmpeg into a terminal, you still use it constantly. It’s the open-source engine that decodes and encodes audio and video, and it’s embedded almost everywhere media plays. Chrome and Firefox lean on it. VLC is built around it. Android ships it. Plex, OBS, ffmpeg-based transcoding farms at streaming companies, your smart TV, the thumbnail generator on a photo site: all FFmpeg or a fork of it. When something turns a file you uploaded into a preview, FFmpeg is often the thing reading those raw bytes.
That ubiquity is exactly what makes it dangerous. Decoding media means parsing complex, untrusted input. A malformed video isn’t just a broken video; it’s an attacker-controlled stream of bytes flowing straight into low-level C code that was written to be fast, not paranoid. DepthFirst’s researcher Zhenpeng Lin put it plainly: FFmpeg “routinely parses complex, untrusted media,” which makes it “inherently security critical and a prime target for zero-click attacks.” Zero-click means nobody has to open anything. The file arrives, your software decodes it to show a preview, and that’s the whole exploit.
The bugs: small inputs, big consequences
The 21 findings are mostly memory-corruption bugs: heap overflows, stack overflows, integer overflows in the parts of FFmpeg that read file and stream structure. Eight got CVE identifiers (CVE-2026-39210 through CVE-2026-39218); the other 13 are tracked internally while patches catch up. They span the TS demuxer, the VP9 decoder, swscale, several RTP depacketizers, the DASH demuxer, and the RTSP and RTMP clients, among others.
The standout is in the AV1 RTP depacketizer, the code that reassembles AV1 video sent over a live stream. A single 183-byte RTP packet, delivered over RTSP with no authentication and no user interaction, is enough to corrupt a function pointer in an adjacent buffer and hand an attacker full control of the instruction pointer. In plain terms: one tiny network packet, and the attacker is running their code on your machine. That’s RCE, the worst class of bug there is.
Some of these flaws are not new. One stack overflow in FFmpeg’s service-description-table parsing dates to 2003 and sat untouched for 23 years. Another reaches back to 2005. They survived two decades partly because nobody was looking at that specific corner of a 1.5-million-line C codebase. The obscure codecs and ancient container formats are the soft underbelly: real code, reachable from untrusted input, that almost no human has audited since it was written.
What’s genuinely new is the cost of finding them. DepthFirst didn’t run classic fuzzing; it used an agentic system that does threat modeling, traces data flow, and produces a concrete reproducer for each bug. The firm pegs the compute bill at roughly $1,000, and notes Anthropic spent about ten times that running a comparable pass with its Mythos model. Whichever number you trust, the takeaway is the same: scanning huge C codebases for memory bugs is now cheap enough that anyone can do it, including the people who don’t file responsible disclosures.
The maintainer problem nobody’s funding
Here’s where the $1,000 stops being a fun stat and starts being a warning. If finding bugs is cheap and automated, the bottleneck moves entirely to fixing them, and fixing them is still slow, manual, human work. For FFmpeg, that work falls on volunteers.
This collided with reality in late 2025, when Google’s AI bug-hunting agent reported a flaw in FFmpeg’s decoder for the LucasArts Smush codec, a format used by the 1995 game Rebel Assault II, affecting the first few frames. FFmpeg’s maintainers were not grateful. They called the report “CVE slop” and made a blunt argument that’s worth quoting directly. “Companies with highly paid engineers are pushing the work onto volunteers,” the project posted. “If Google really wants to prevent risk, they should write and submit patches.” And the sharpest line: “They’re not really interested in fixing bugs; they just want to build a track record of detecting and reporting them.”
You can feel the frustration. The official position is careful, though. “Security issues are taken extremely seriously in FFmpeg,” the project wrote, “but fixes are written by volunteers.” That’s the whole tension in one sentence. A trillion-dollar company runs a tool that finds a hundred bugs an hour, files them all, and walks away. The unpaid maintainer who has a day job and a family is now on the hook to triage, reproduce, fix, and review every one, including the medium-impact flaw in a codec for a 31-year-old game almost nobody plays.
This isn’t unique to FFmpeg. The maintainer of libxml2 quit in 2025 over the same dynamic: an endless queue of security reports, no compensation, and downstream giants who treat the project as free infrastructure. FFmpeg powers a chunk of Google’s own products. So does libxml2. The pattern repeats across the libraries holding up the modern stack.
Who’s exposed, and what to actually do
If you ship anything that decodes media you didn’t create, you inherit this attack surface. That’s a long list: anyone running a media server, an upload pipeline that generates thumbnails or transcodes, a WebRTC or RTSP service, a chat app that previews shared videos. The blast radius isn’t “people who use FFmpeg on purpose.” It’s everyone who pulled it in through a dependency and never thought about it.
You can’t patch your way out of an attack surface this size, and you can’t drop FFmpeg either. So defense is about containment, not elimination:
- Sandbox the decoder. Run media decoding in an isolated, low-privilege process (seccomp, a container, a separate user) so an RCE in FFmpeg can’t reach the rest of your system. This is the single highest-value move.
- Disable what you don’t use. FFmpeg builds can be compiled with only the codecs and demuxers you actually need. If you never handle RTSP or AV1-over-RTP, don’t ship the parser that just got popped.
- Treat all input as hostile. Validate and constrain formats at the edge. Don’t let an arbitrary uploaded file pick which decoder runs.
- Track the CVEs. Watch for the patched FFmpeg release that closes CVE-2026-39210 through 39218 and upgrade, but understand that’s cleanup, not a cure.
For a sense of how these supply-chain flaws ripple outward, our coverage of a single header that bypassed auth across millions of AI agents and a VS Code zero-day that stole GitHub tokens shows the same shape: one flaw in shared code, an enormous downstream inheritance.
What this means for you
If you build anything that touches media, assume FFmpeg is in your stack and assume it’s attackable, because it is. The 21 zero-days are a snapshot, not the total; the next agent run will find more, and the one after that. Your job isn’t to win that race. It’s to make a single decoder bug survivable: sandbox the process, strip the codecs you don’t use, and never decode a stranger’s file next to anything you’d hate to lose.
The harder problem is the one you can’t fix from your own repo. The economics of finding bugs just collapsed, the economics of fixing them didn’t budge, and the gap lands on volunteers who were already underwater. Watch whether the companies that depend on FFmpeg start funding it, or whether they keep treating a handful of unpaid maintainers as their free security team. The disclosure researchers and FFmpeg’s own maintainers, who’ve publicly clashed with GitHub and Big Tech over exactly this dynamic, agree on at least one thing: the current arrangement doesn’t hold.
Share this article
Quick reference
Sources
- Twenty One Zero-Days in FFmpeg — DepthFirst
- FFmpeg thanks Google for the bug reporting, now asks where the funding is — TechSpot
- 21 0-Day Vulnerabilities in FFmpeg Enables Remote Code Execution Attacks — Cyber Security News
- FFmpeg to Google: Fund Us or Stop Sending Bugs — The New Stack
Frequently Asked
- What is FFmpeg and why is it everywhere?
- FFmpeg is the open-source library that decodes and encodes audio and video. Browsers, VLC, Chrome, Android, servers, and most streaming apps embed it, so a parsing bug in FFmpeg can reach billions of devices that never installed it directly.
- Are the 21 zero-days actively being exploited?
- There's no public evidence of in-the-wild exploitation yet. They were found by a security agent, responsibly disclosed, and several already have patches. The risk is that the proof-of-concept inputs are now public and the underlying attack surface is huge.
- Should I stop using FFmpeg?
- No. Almost nothing in media would work without it, and pulling it isn't realistic. The practical move is to sandbox the decoding process, disable codecs and demuxers you don't need, and never decode untrusted media in the same process as sensitive data.
- Why are FFmpeg maintainers upset with Google?
- Google's AI tools report a flood of bugs, including low-impact ones in decade-old game codecs, but the company doesn't fund the volunteers who write the fixes. FFmpeg's position: if a trillion-dollar firm relies on the code, it should ship patches or pay, not just file reports.
- Did AI really find these bugs cheaper than humans?
- DepthFirst put its full run at roughly $1,000 in compute, well under what a manual audit of 1.5 million lines of C would cost. The catch is that the same economics let attackers scan the same code just as cheaply.