Android·
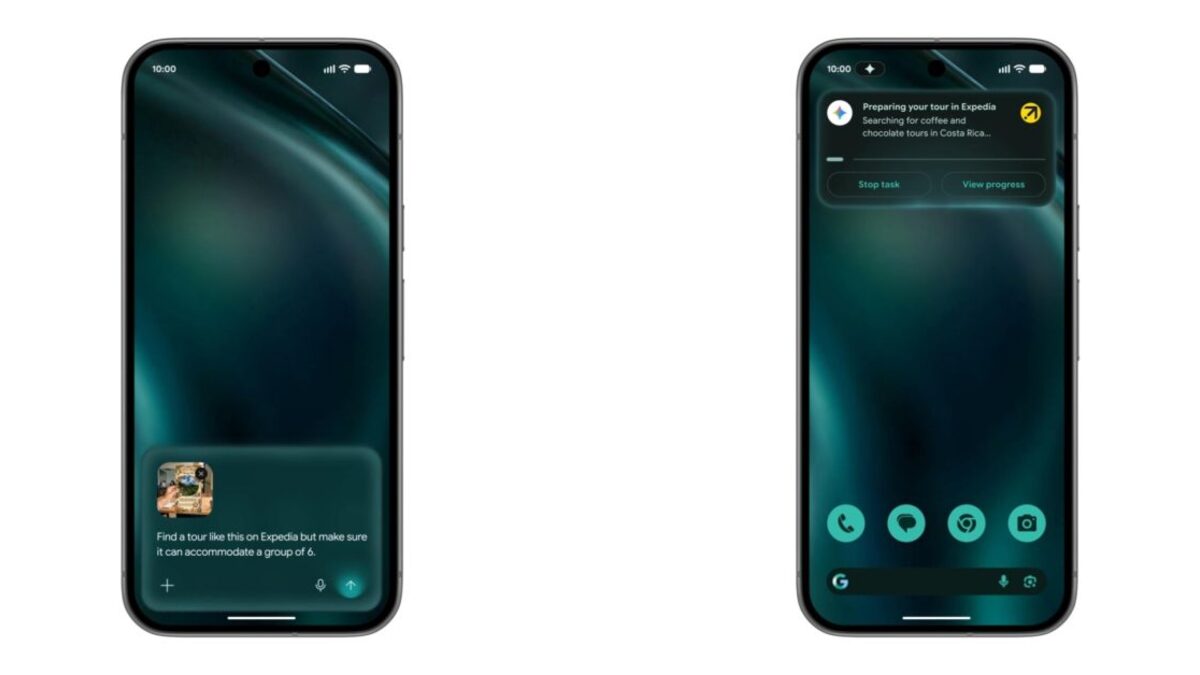
Gemini Intelligence turns Android 17 into an agent that drives your apps
Google's Android Show pitched Gemini Intelligence and AppFunctions, an MCP-style way for the assistant to call inside your apps. Here's how it works and what to watch.
Large language model releases, benchmarks, capability jumps, and the infrastructure that runs them.
Google's Android Show pitched Gemini Intelligence and AppFunctions, an MCP-style way for the assistant to call inside your apps. Here's how it works and what to watch.

A popular Hacker News how-to walked through a fully local coding agent on Apple Silicon. Here's the realistic 2026 stack: runner, model, and harness.

Claude Fable 5 hits 80.3% on SWE-Bench Pro and ships on Bedrock and Copilot at $10/$50 per million tokens, free on paid plans only through June 22.

OpenAI shipped Lockdown Mode in ChatGPT to cut off the data-exfiltration step of prompt-injection attacks. Here's what it actually restricts and who should turn it on.

On June 2 OpenAI said Codex is coming to the ChatGPT app everywhere within weeks, and shipped six role-specific plugins for sales, analytics, design, and finance teams.

A blinded Stanford Law study had 16 professors grade AI tutoring answers against their own. Here's what the 75% win rate actually measures, and what it doesn't.

Anthropic's Opus 4.8 posts 69.2% on SWE-Bench Pro, lets code flaws slip 4x less often, and ships parallel subagents in Claude Code. Here's what matters.
Two of the most cautious C projects split on AI contributions in the same week. The real fight is over copyright provenance and who cleans up the slop.
Six dev-tooling and AI posts that climbed Hacker News in late May 2026: durable execution on plain Postgres, LLM code smells, a permission-fatigue game, Rust 1.96, and more.

On May 23 DeepSeek told customers the V4-Pro discount becomes its standard price after May 31. Output drops from $3.48 to $0.87 per million tokens.
Karpathy started this week at Anthropic on Nick Joseph's pre-training team. His mandate is using Claude to accelerate Claude's own training.

Cyera disclosed CVE-2026-7482 on May 1, a CVSS 9.1 unauthenticated heap read in Ollama. Three API calls dump prompts, env vars, and API keys from any open instance.
The DELEGATE-52 benchmark tests AI editing across 52 professional domains. Frontier models corrupt a quarter of document content over long workflows.

The 1998 Fields Medal winner reports GPT 5.5 Pro produced a novel proof for an unsolved math problem in 17 minutes, and says the era of owning theorems is ending.

Microsoft loses exclusive rights to OpenAI's models. The revenue share now caps at 2030 and stops depending on AGI. Here's what actually changed and who it benefits.

Arcee released Trinity-Large-Thinking on April 1: a 399B-param sparse MoE with 13B active, Apache 2.0 weights, $0.88 per million output tokens, and PinchBench just behind Opus 4.6.

SGLang's reranker renders chat templates without a sandbox. Load a hostile GGUF, hit /v1/rerank, and the attacker has Python on your inference box. No patch yet.

OpenAI says SWE-bench Verified is saturated and contaminated, and 60% of remaining problems are unsolvable. Here's what comes next, and why every coding leaderboard is suspect.